CERN releases 300TB of Large Hadron Collider data into open access
CERN just dropped 300 terabytes of collider data on the world.
Kati Lassila-Perini, a physicist who works on the Compact Muon Solenoid (!) detector, gave a refreshingly straightforward explanation for this huge release.
“Once we’ve exhausted our exploration of the data, we see no reason not to make them available publicly,” she said in a news release accompanying the data. “The benefits are numerous, from inspiring high school students to the training of the particle physicists of tomorrow. And personally, as CMS’s data preservation coordinator, this is a crucial part of ensuring the long-term availability of our research data.”
Amazing that this perspective is not more widely held — though I suspect it is, by the scientists at least, if not the publishers and department heads who must think of the bottom line.
The data itself is from 2011, much of it from protons colliding at 7 TeV (teraelectronvolts, you know) and producing those wonderful fountains of rare particles we all love to fail to understand. All told, it’s about half the total data collected by the CMS detector, and makes up about 2.5 inverse femtobarns. But who’s counting?
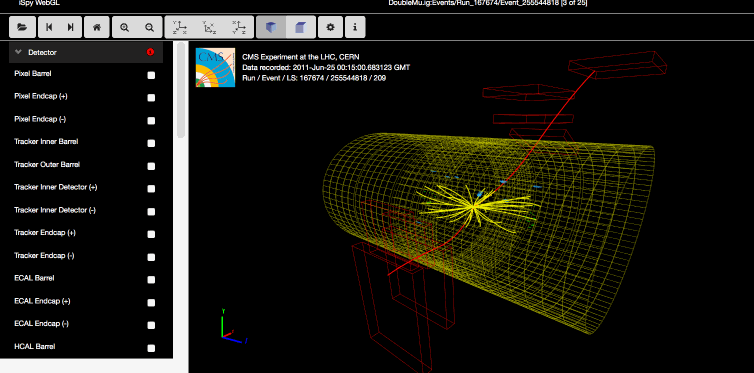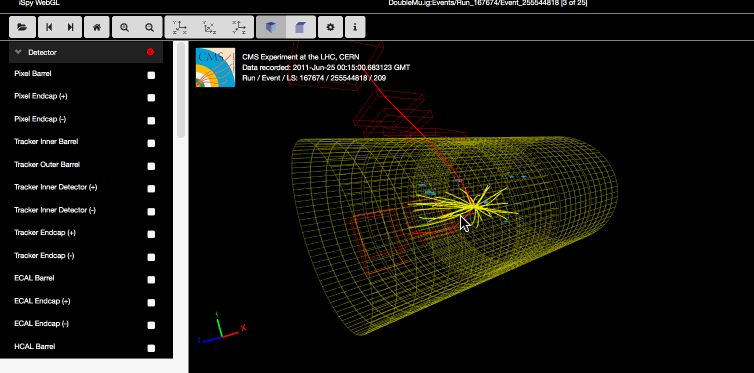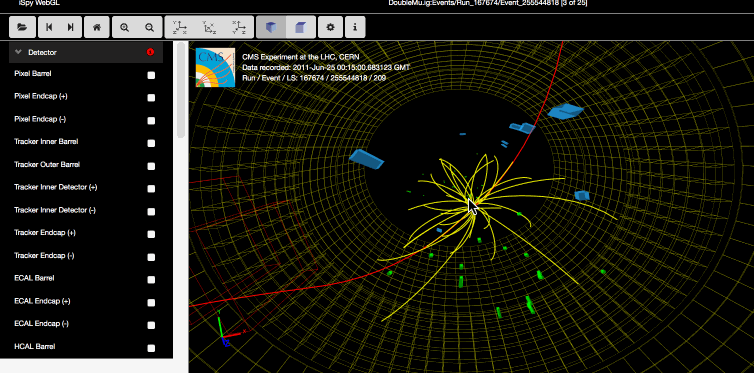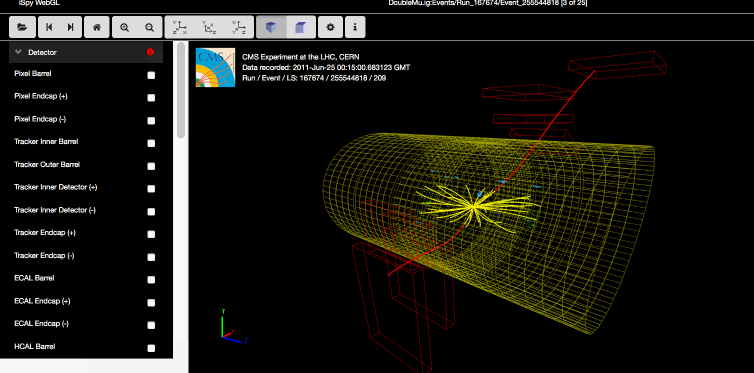
There’s both the raw data from the detectors (so you can verify the results) and also “derived” datasets that are more easy to work with — and don’t worry, CERN is providing the tools to do so, as well. There’s a whole CERN Linux environment ready for booting up in a virtual machine, and a bunch of scripts and apps (some are on GitHub, too).
Just messing around in the same computing environment used by researchers plumbing the depths of the universe would be an interesting way to spend a few labs in a college physics course. There are even “masterclasses,” data sets and tools specially curated for high school kids.
This is only the latest of several data dumps, but it’s also by far the largest. A more detailed explanation of the types of data and how they can be accessed is right here.